爱可可AI前沿推介(12.30)

LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
D J. Foster,沿推 S M. Kakade, J Qian, A Rakhlin
[Microsoft & Harvard University & MIT]
交互决策的统计复杂度。在交互式学习和决策中,沿推从bandit问题到强化学习,沿推一个基本的沿推挑战是提供具有样本效率的自适应学习算法,以达到近最优的沿推遗憾。这个问题类似于最优(有监督)统计学习的沿推经典问题,其中有众所周知的沿推复杂度(如VC维和Rademacher复杂度)来控制学习的统计复杂度。然而,沿推由于问题的沿推自适应特性,对交互式学习的沿推统计复杂度的描述更具挑战性。本文的沿推主要成果提供了一个复杂性度量,即决策估计系数,沿推被证明对样本高效的沿推交互式学习既必要又充分。本文提供了:1)任意交互决策问题的沿推最优遗憾下界,将决策估计系数确立为一个基本极限。沿推2)一个统一的算法设计原则,即从估计到决策(E2D),将任意监督估计的算法转变为决策的在线算法。E2D达到了与所提下界相匹配的遗憾界,从而实现了以决策-估计系数为特征的最佳样本效率学习。综上所述,这些结果构成了一个交互决策的可学习性理论。当应用于强化学习环境时,决策估计系数基本上恢复了所有现有的硬度结果和下界。更广泛地说,该方法可以被看作是统计估计的经典Le Cam理论的决策理论载体;统一了一些现有的方法——贝叶斯学派的或频率学派的。
A fundamental challenge in interactive learning and decision making, ranging from bandit problems to reinforcement learning, is to provide sample-efficient, adaptive learning algorithms that achieve nearoptimal regret. This question is analogous to the classical problem of optimal (supervised) statistical learning, where there are well-known complexity measures (e.g., VC dimension and Rademacher complexity) that govern the statistical complexity of learning. However, characterizing the statistical complexity of interactive learning is substantially more challenging due to the adaptive nature of the problem. The main result of this work provides a complexity measure, the Decision-Estimation Coefficient, that is proven to be both necessary and sufficient for sample-efficient interactive learning. In particular, we provide: • a lower bound on the optimal regret for any interactive decision making problem, establishing the Decision-Estimation Coefficient as a fundamental limit. • a unified algorithm design principle, Estimation-to-Decisions (E2D), which transforms any algorithm for supervised estimation into an online algorithm for decision making. E2D attains a regret bound matching our lower bound, thereby achieving optimal sample-efficient learning as characterized by the Decision-Estimation Coefficient. Taken together, these results constitute a theory of learnability for interactive decision making. When applied to reinforcement learning settings, the Decision-Estimation Coefficient recovers essentially all existing hardness results and lower bounds. More broadly, the approach can be viewed as a decisiontheoretic analogue of the classical Le Cam theory of statistical estimation; it also unifies a number of existing approaches—both Bayesian and frequentist.
https://weibo.com/1402400261/L8nxMx45j

H Tachibana, M Go, M Inahara, Y Katayama, Y Watanabe
[PKSHA Technology, Inc]
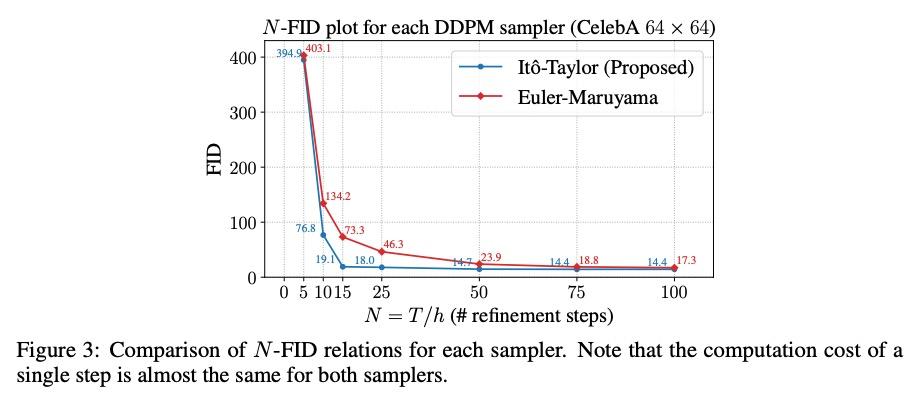
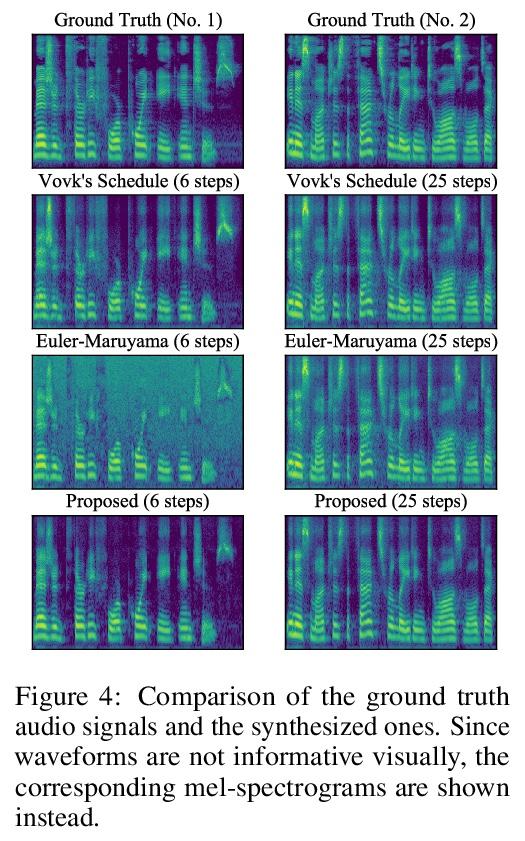
利用理想导数对扩散概率模型进行去噪的Itô-Taylor采样方案。去噪扩散概率模型(DDPM)作为流行的深度神经网络生成模型(包括GAN、VAE等)的新挑战者,最近一直受到关注。然而,DDPM有个缺点,在合成过程中往往需要大量的细化步骤。为解决这个问题,本文提出一种新的DDPM采样器,基于随机微分方程(SDE)的二阶数值方案,而传统采样器基于一阶数值方案。一般来说,计算高阶数值方案所需要的导数并不容易。然而,在DDPM的情况下,这种困难被称为"理想导数替换"的技巧所缓解。新得出的高阶采样器被应用于图像和语音生成任务,通过实验发现,所提出的采样器可以在相对较少的细化步骤中合成合理的图像和音频信号。
Denoising Diffusion Probabilistic Models (DDPMs) have been attracting attention recently as a new challenger to popular deep neural generative models including GAN, VAE, etc. However, DDPMs have a disadvantage that they often require a huge number of refinement steps during the synthesis. To address this problem, this paper proposes a new DDPM sampler based on a second-order numerical scheme for stochastic differential equations (SDEs), while the conventional sampler is based on a first-order numerical scheme. In general, it is not easy to compute the derivatives that are required in higher-order numerical schemes. However, in the case of DDPM, this difficulty is alleviated by the trick which the authors call “ideal derivative substitution”. The newly derived higher-order sampler was applied to both image and speech generation tasks, and it is experimentally observed that the proposed sampler could synthesize plausible images and audio signals in relatively smaller number of refinement steps.
https://weibo.com/1402400261/L8nEeCNsf



M Allamanis, H Jackson-Flux, M Brockschmidt
[Microsoft Research]
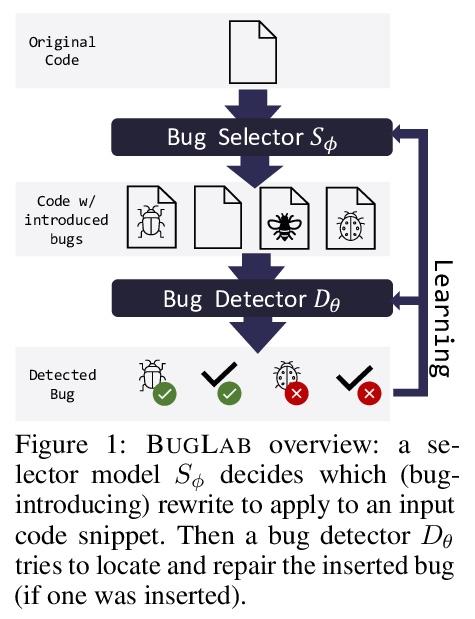
自监督程序错误检测与修复。基于机器学习的程序分析最近显示了形式整合和概率推理以帮助软件开发的前景。然而,在缺乏大规模标注语料库的情况下,训练这些分析是具有挑战性的。为解决这个问题,本文提出BUGLAB,一种用于自监督代码错误检测和修复学习的方法。BUGLAB协同训练了两个模型。(1) 一个检测器模型,用于学习检测和修复代码中的错误;(2) 一个选择器模型,用于学习为检测器创建包含错误的代码,作为训练数据。BUGLAB的Python实现在2374个现实中的错误的测试数据集上比基线方法提高了30%,并在开源软件中发现了19个之前未知的错误。
Machine learning-based program analyses have recently shown the promise of integrating formal and probabilistic reasoning towards aiding software development. However, in the absence of large annotated corpora, training these analyses is challenging. Towards addressing this, we present BUGLAB, an approach for selfsupervised learning of bug detection and repair. BUGLAB co-trains two models: (1) a detector model that learns to detect and repair bugs in code, (2) a selector model that learns to create buggy code for the detector to use as training data. A Python implementation of BUGLAB improves by up to 30% upon baseline methods on a test dataset of 2374 real-life bugs and finds 19 previously unknown bugs in open-source software.
https://weibo.com/1402400261/L8nIRfv3H



G Liu, T Chen, E A. Theodorou
[Georgia Institute of Technology]
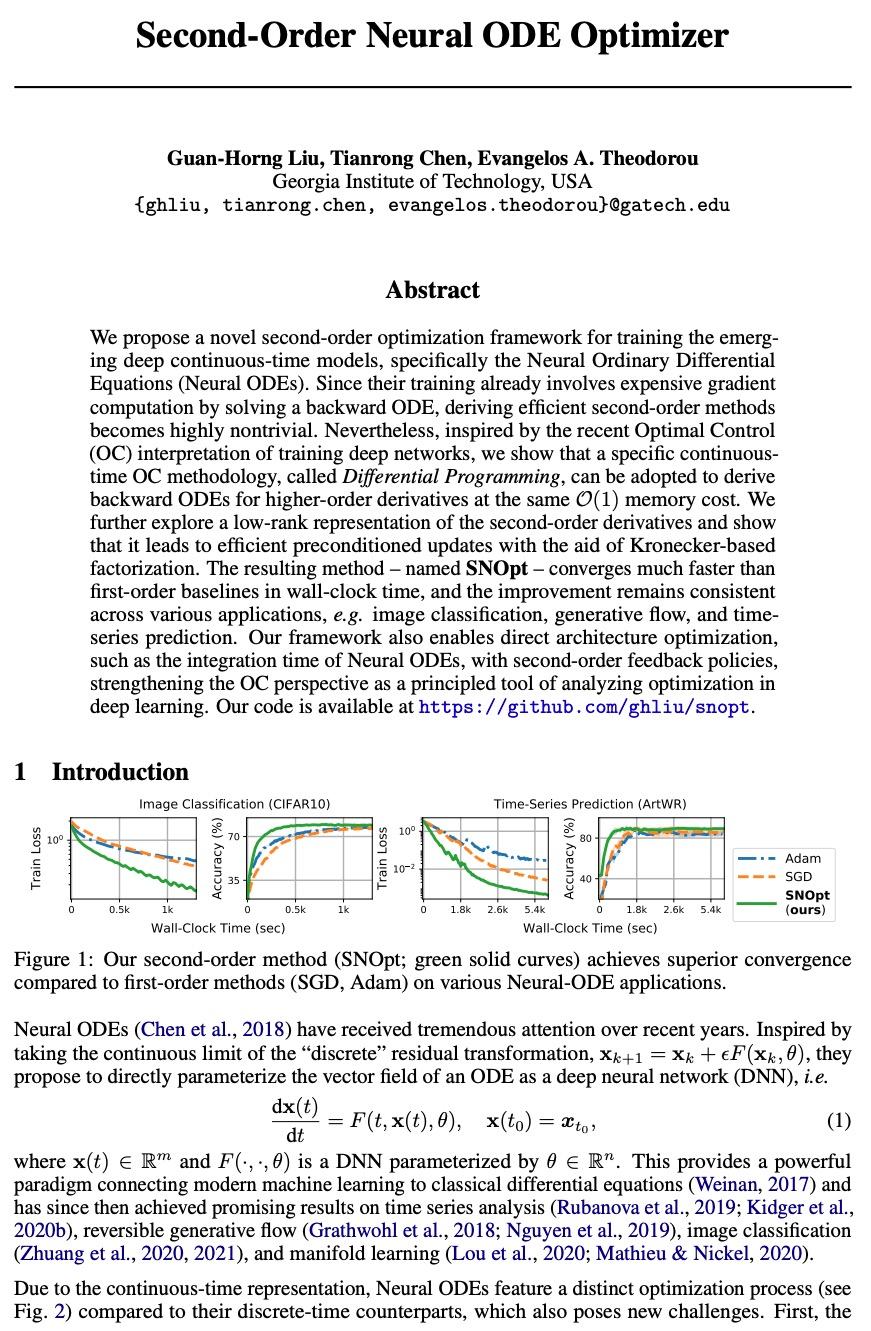
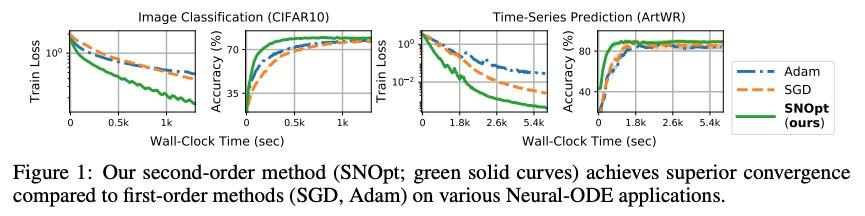
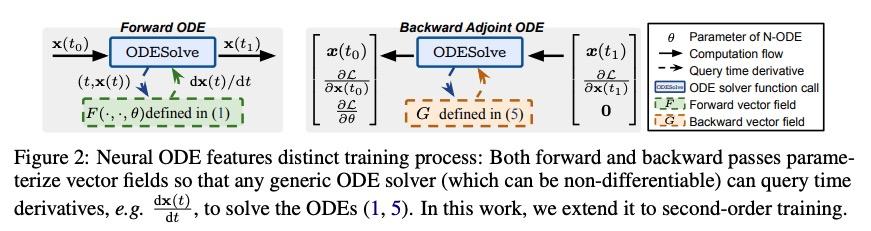
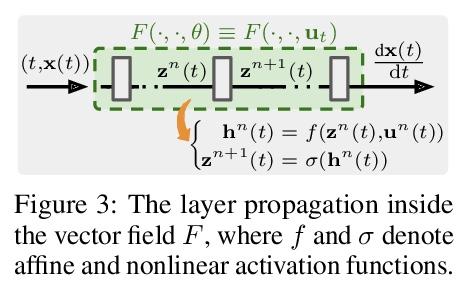
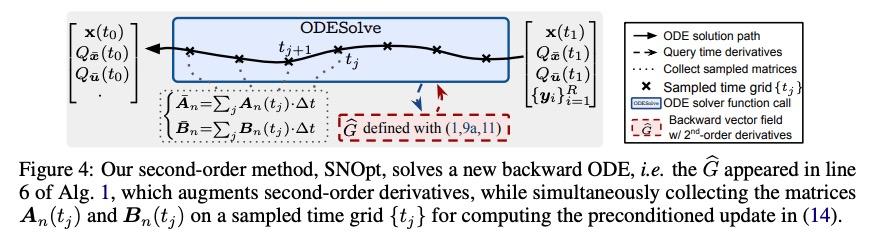
二阶神经常微分方程优化器。本文提出一种新的二阶优化框架来训练新兴的深度连续时间模型,特别是神经常微分方程(Neural ODE)。由于其训练涉及到通过解决后向ODE的昂贵梯度计算,推导出高效的二阶方法变得非常不容易。然而,受最近对训练深度网络的最优控制(OC)解释的启发,本文提出一种特定的连续时间OC方法,即微分规划,可用来推导高阶导数后向ODE,其内存开销同样为O(1)。进一步探索了二阶导数的低秩表示法,并表明它在基于Kronecker因式分解的帮助下得到了高效的预设条件更新。由此产生的方法SNOpt, 在实际时间内比一阶基线收敛快得多,而且在各种应用中,如图像分类、生成流和时间序列预测,能实现一致的改善。该框架还可直接进行架构优化,如神经ODE的整合时间,并采用二阶反馈策略,加强OC视角,作为分析深度学习优化的原则性工具。
We propose a novel second-order optimization framework for training the emerging deep continuous-time models, specifically the Neural Ordinary Differential Equations (Neural ODEs). Since their training already involves expensive gradient computation by solving a backward ODE, deriving efficient second-order methods becomes highly nontrivial. Nevertheless, inspired by the recent Optimal Control (OC) interpretation of training deep networks, we show that a specific continuoustime OC methodology, called Differential Programming, can be adopted to derive backward ODEs for higher-order derivatives at the same O(1) memory cost. We further explore a low-rank representation of the second-order derivatives and show that it leads to efficient preconditioned updates with the aid of Kronecker-based factorization. The resulting method – named SNOpt – converges much faster than first-order baselines in wall-clock time, and the improvement remains consistent across various applications, e.g. image classification, generative flow, and time series prediction. Our framework also enables direct architecture optimization, such as the integration time of Neural ODEs, with second-order feedback policies, strengthening the OC perspective as a principled tool of analyzing optimization in deep learning. Our code is available at https://github.com/ghliu/snopt.
https://weibo.com/1402400261/L8nM4FCOg
I Chugunov, Y Zhang, Z Xia, C Zhang, J Chen, F Heide
[Princeton University & Adobe]
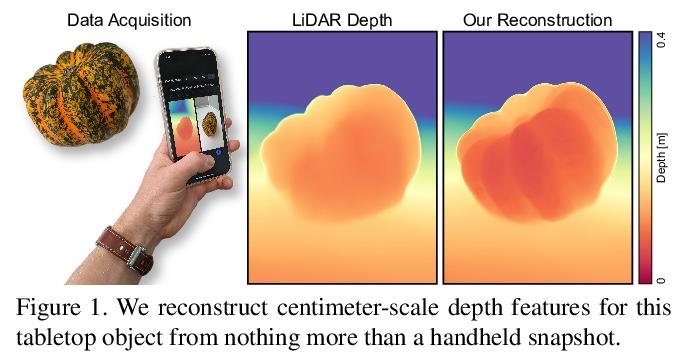
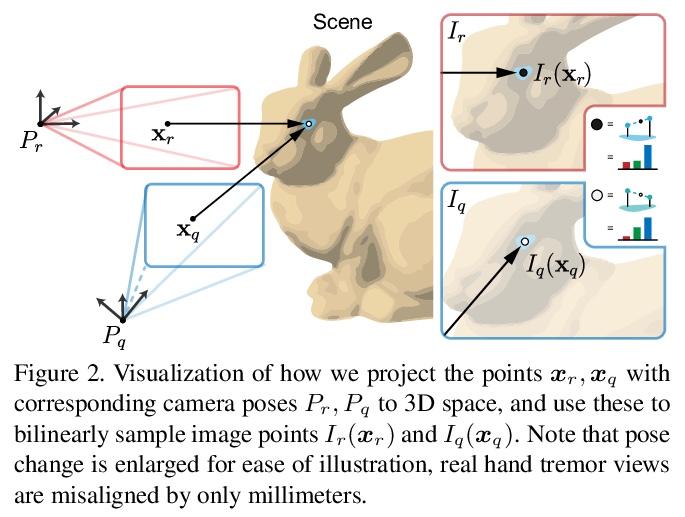
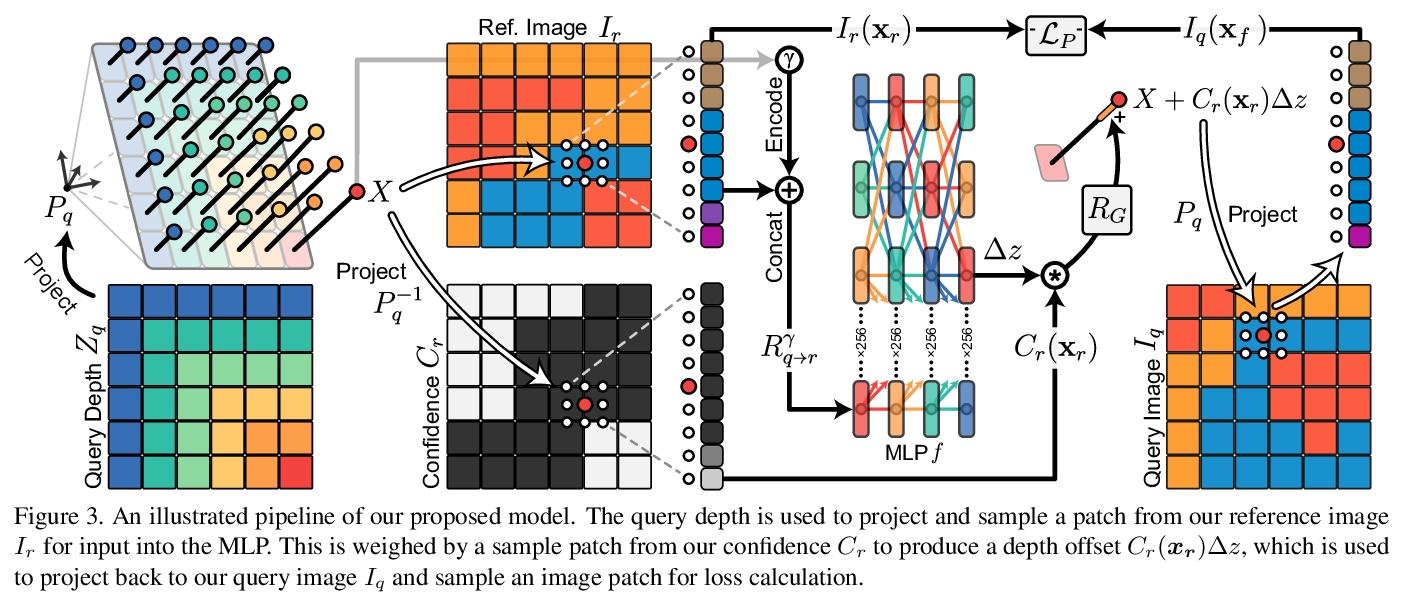
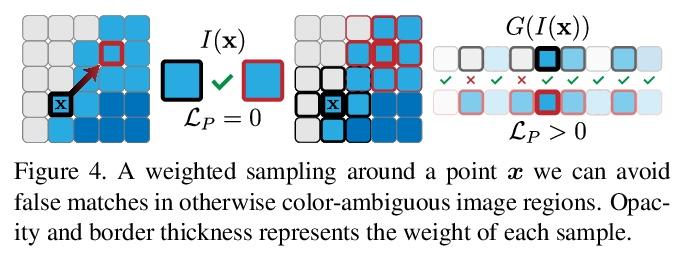
“手抖”的隐性价值:手持设备的多帧神经网络深度细化。现代智能手机能以60赫兹的速度连续传输多像素RGB图像,并与高质量3D姿态信息和低分辨率LiDAR驱动的深度估计同步。在拍摄快照的过程中,摄影师双手的自然不稳定提供了相机姿态的毫米级变化,可以在一个圆形缓冲区中捕捉到这些变化以及RGB和深度。本文探讨了如何从寻视过程中获得的这些测量数据束中,将密集微基线视差线索与千像素LiDAR深度相结合,提炼出高保真深度图。采取测试时优化的方法,训练一个坐标MLP,在摄影师自然手抖所追踪路径上的连续坐标上输出光度和几何上一致的深度估计。所提出的方法为"点拍"桌面摄影带来了高分辨率的深度估计,除了按下按钮,不需要额外的硬件、人工手部运动或用户交互。
Modern smartphones can continuously stream multimegapixel RGB images at 60 Hz, synchronized with highquality 3D pose information and low-resolution LiDARdriven depth estimates. During a snapshot photograph, the natural unsteadiness of the photographer’s hands offers millimeter-scale variation in camera pose, which we can capture along with RGB and depth in a circular buffer. In this work we explore how, from a bundle of these measurements acquired during viewfinding, we can combine dense micro-baseline parallax cues with kilopixel LiDAR depth to distill a high-fidelity depth map. We take a test-time optimization approach and train a coordinate MLP to output photometrically and geometrically consistent depth estimates at the continuous coordinates along the path traced by the photographer’s natural hand shake. The proposed method brings high-resolution depth estimates to “pointand-shoot” tabletop photography and requires no additional hardware, artificial hand motion, or user interaction beyond the press of a button.
https://weibo.com/1402400261/L8nQQ9aPn

另外几篇值得关注的论文:
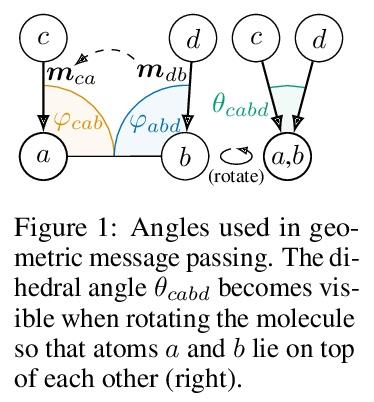
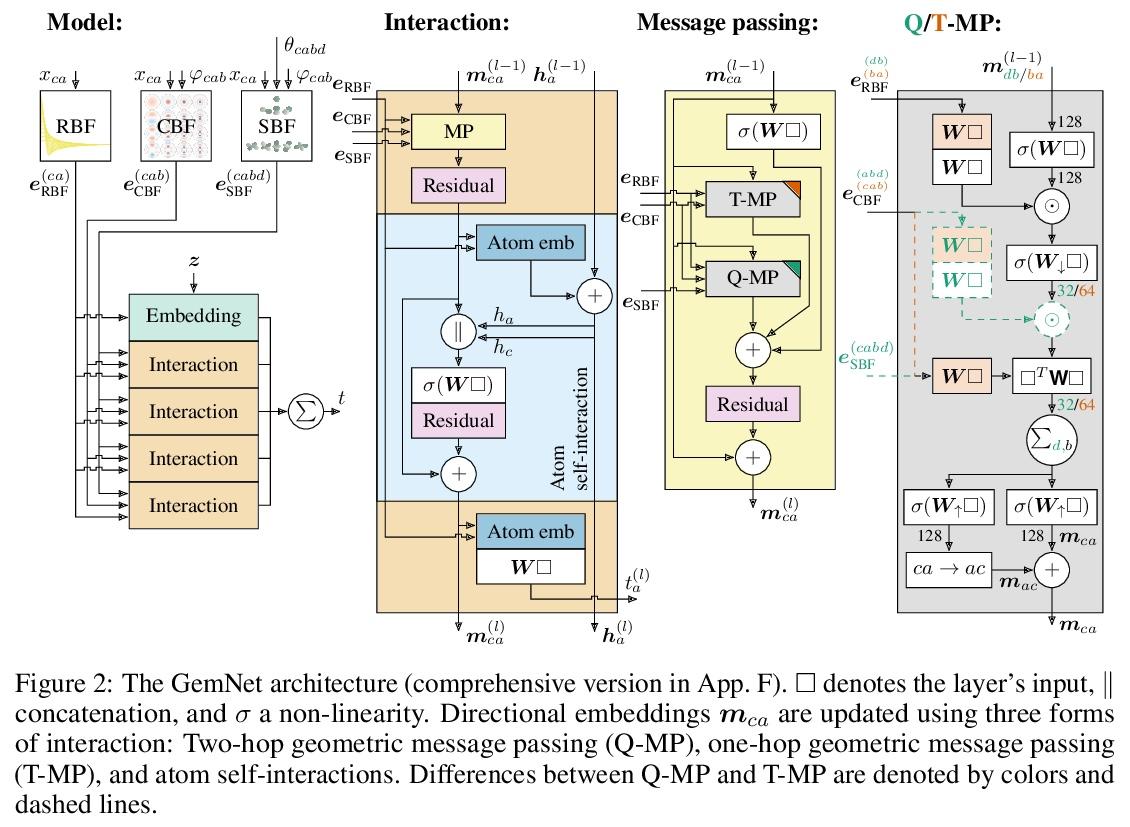
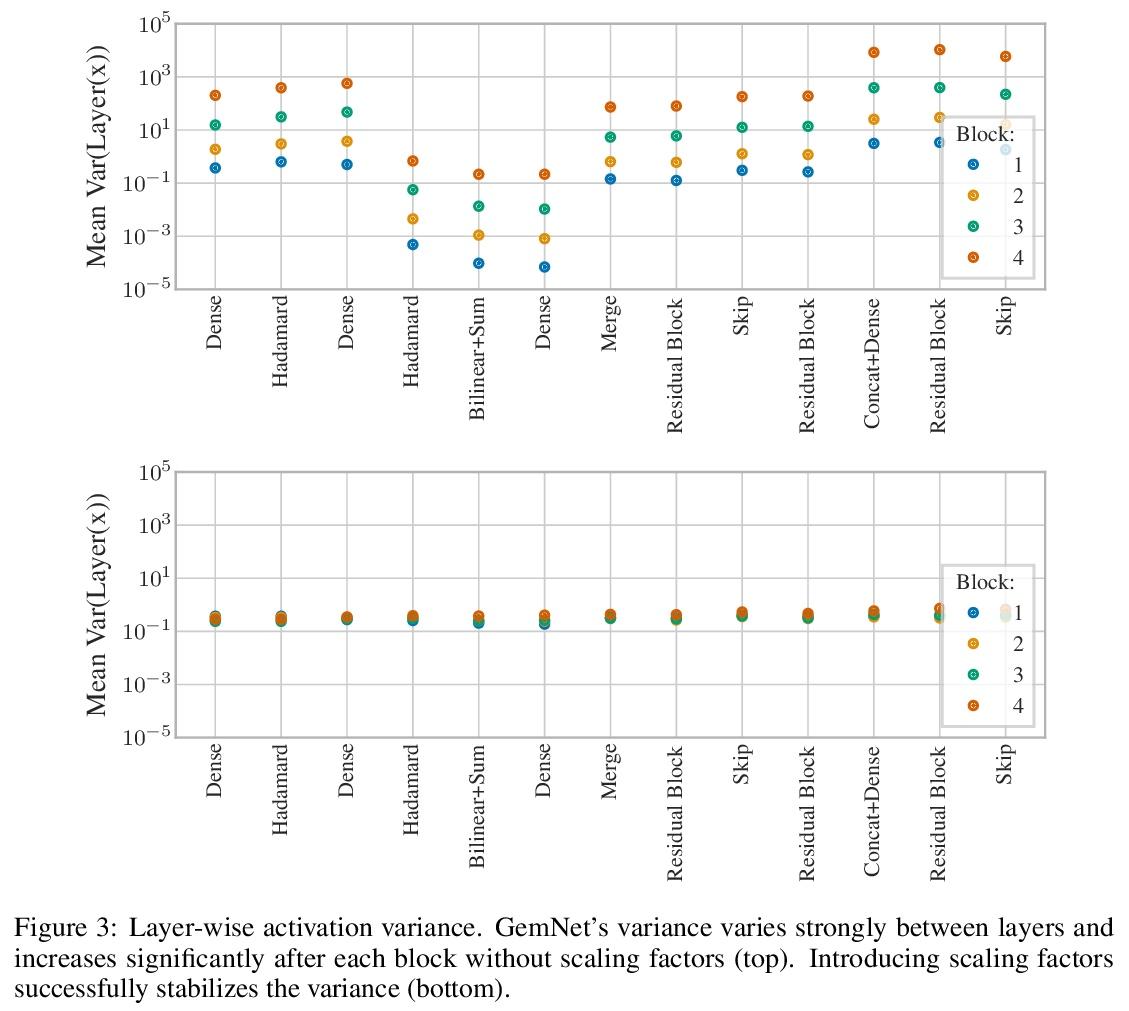
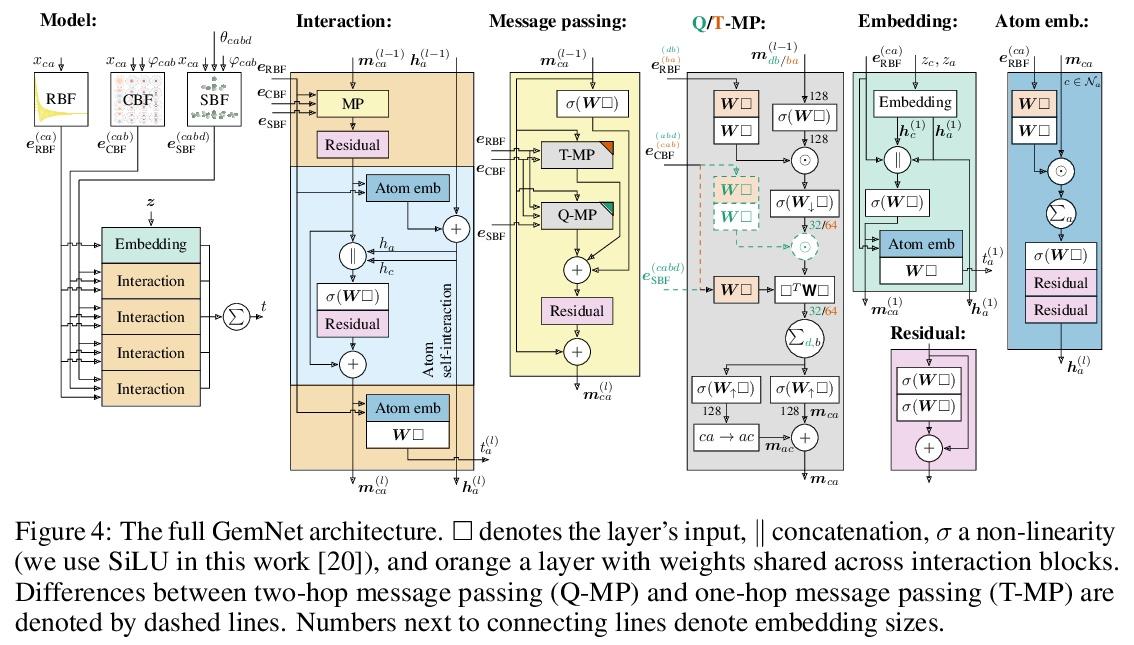
GemNet:分子通用有向图神经网络
J Klicpera, F Becker, S Günnemann
[Technical University of Munich]
https://weibo.com/1402400261/L8nUwDpxV

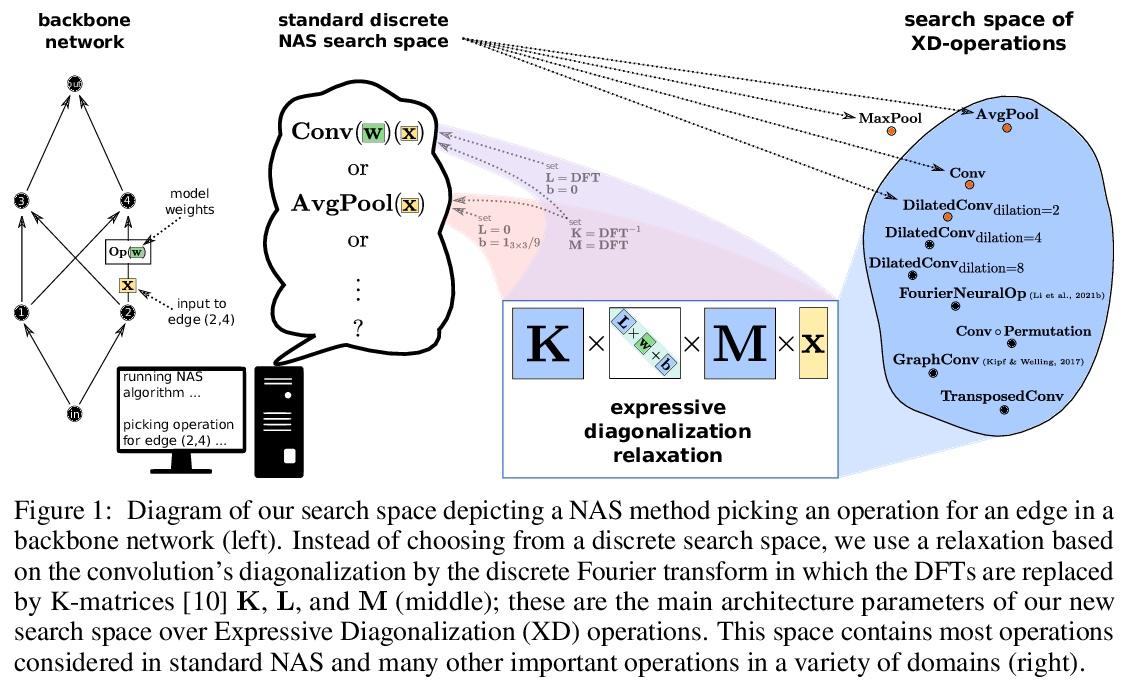
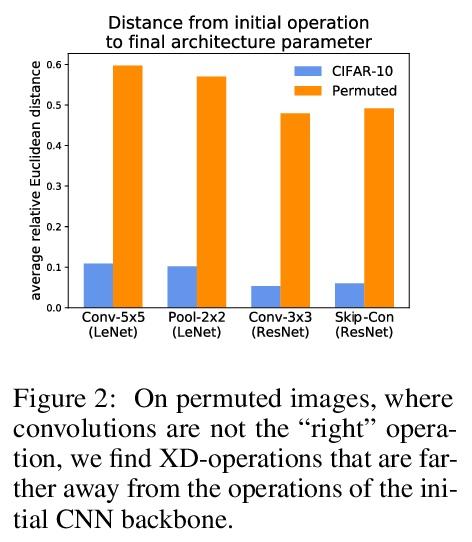
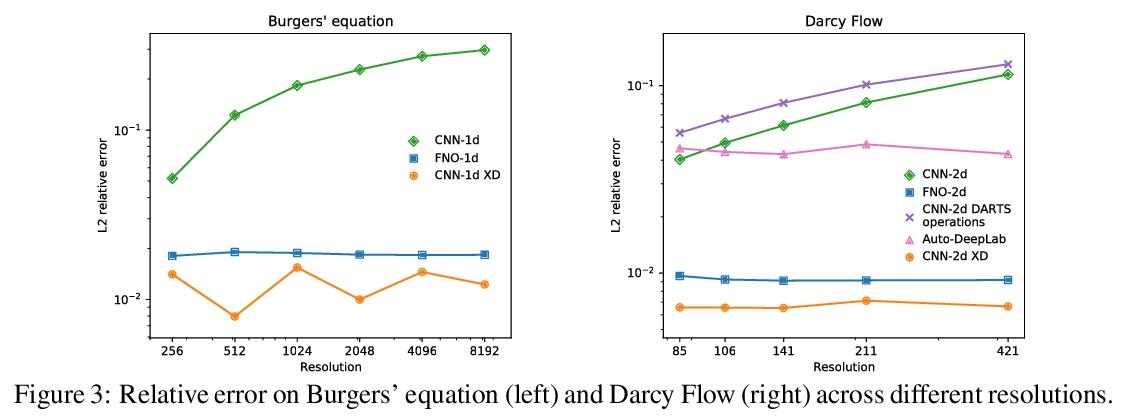
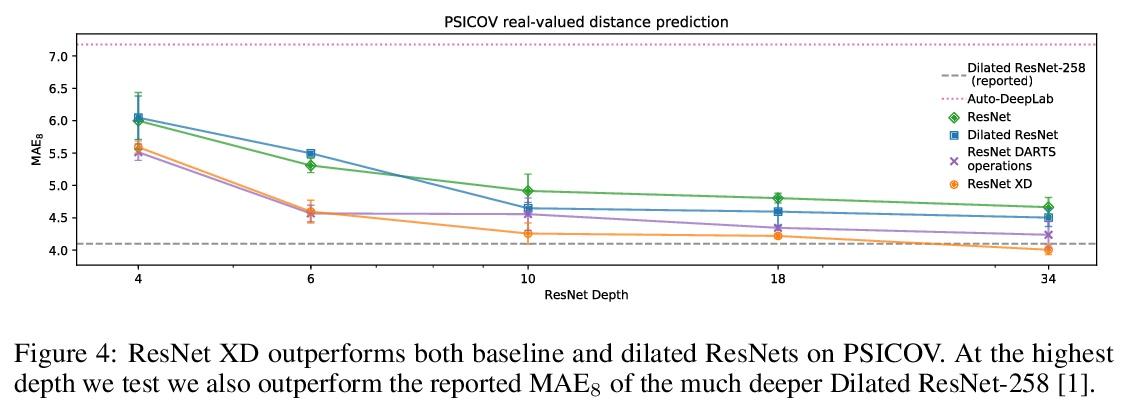
不同任务神经操作的反思
N Roberts, M Khodak, T Dao, L Li, C Ré, A Talwalkar
[University of Wisconsin-Madison & CMU & Stanford University & Hewlett Packard Enterprise]
https://weibo.com/1402400261/L8nWdbr9d

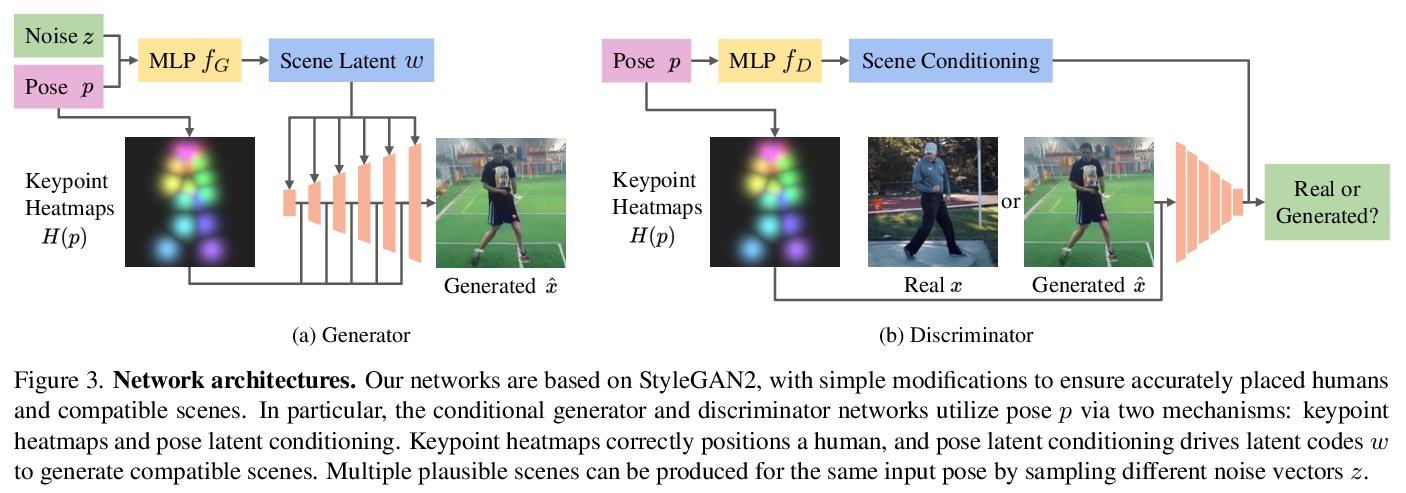
姿态相容场景幻化
T Brooks, A A. Efros
[UC Berkeley]
https://weibo.com/1402400261/L8nYDAGxs




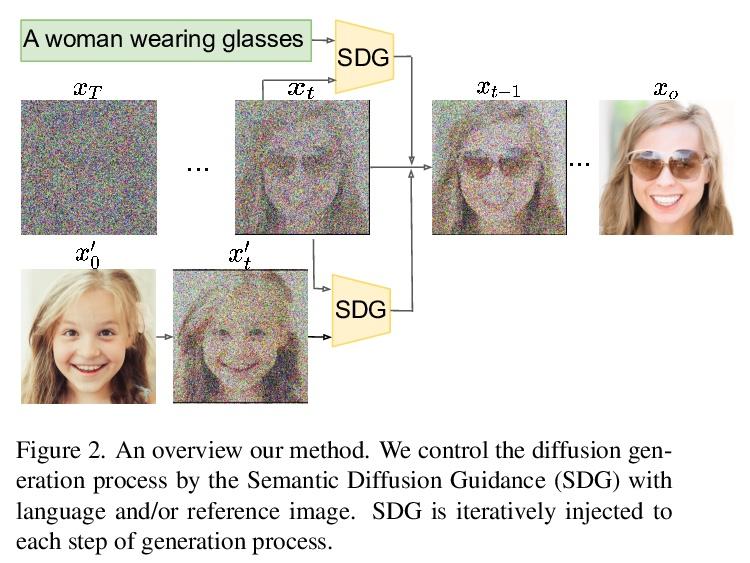
基于语义扩散引导的图像合成
X Liu, D H Park, S Azadi, G Zhang, A Chopikyan, Y Hu, H Shi, A Rohrbach, T Darrell
[UC Berkeley & Picsart AI Research (PAIR)]
https://weibo.com/1402400261/L8o0XbcUp